Setting Up Evaluations
Evaluations are crucial as they ensure our ChatBot functions correctly, bolstering our confidence that it is production-ready. Evaluations scrutinize for errors, biases, and potential risks, and can prevent incorrect responses from reaching our users.
For example one Evaluation we will add is called 'Faithfulness'.
Faithfulness
Faithfulness checks if the answer given by the chatbot matches the information it was based on. We figure this out by comparing the chatbot's answer to the original information. We give the answer a score between 0 and 1, where 1 means it's totally accurate.
An answer is seen as faithful if everything it says can be backed up by the original information (the results from the our Index query). To do this, we first pick out the main points the chatbot's answer is making. Then, we check these points against the original information to see if they really came from there. The faithfulness score is calculated by dividing the number of accurate points in the chatbot's answer by the total points made by the chatbot. By default we pass if the score is over .9 but this can be configured.
Let's clone the following Evaluations to your Project.
To clone to your project, click the Start Using link, then select your project in the dialog.
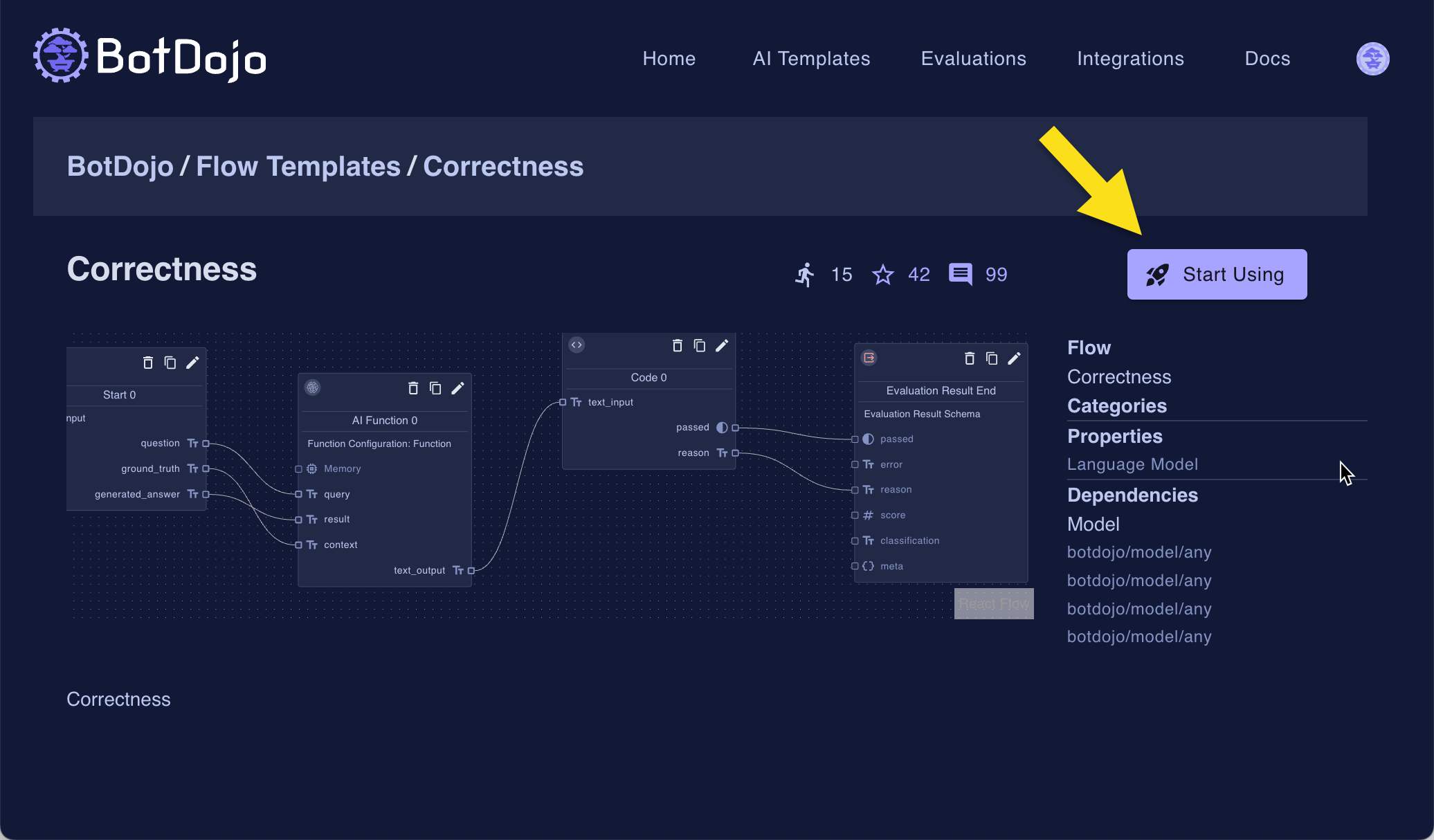
Do this for each of the Evaluations above.
In BotDojo, Evaluations are special Flows that return values that we can use to 'evaluate' other Flows. They often use LLMs to check , but they don't have to. Once you have them in your account, your Flow list should look like this.
In BotDojo, Evaluations are special flows that return values that we can use to grade other Flows. They often use LLMs to check, but they don't have to.
Once you have them in your account, your Flow list should look like this.
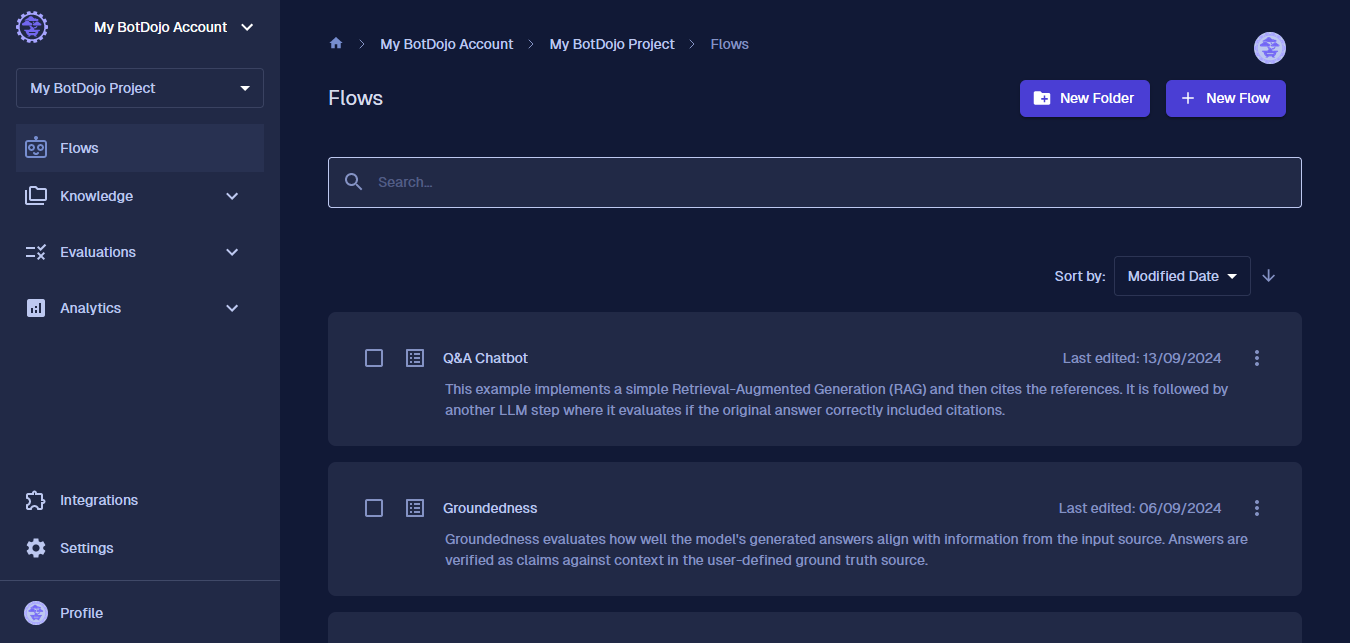
Next, click on our ChatBot and click the Evaluation Navigation menu.
-7f6527600065023ec8b0d6779d2d84c7.gif)
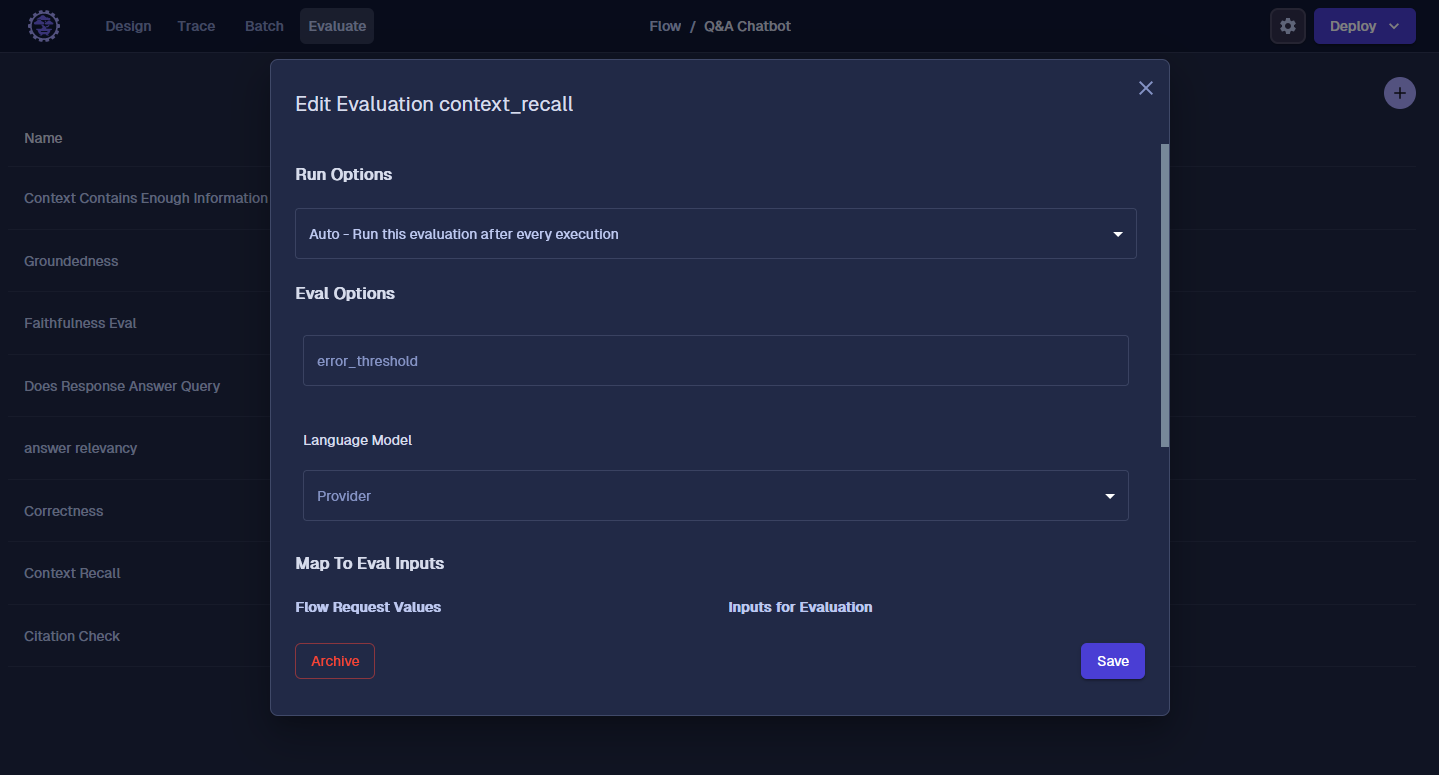
Next, click Add New, then select Context Recall. Now we need to map Parameters from our ChatBot to the Evaluation Function. For the 'context recall' Evaluation, it needs the question, context (the Data we pulled from the Index) to evaluate our ChatBot had enough information to answer the question.
Hit “save”, and next let’s add the Correctness Eval. The Correctness Eval compares the ground truth (right answer) to the one that was generated from our ChatBot. In this scenario, our Flow doesn't know the ground truth, so we want to select "not mapped". We will go over this later in Batches.
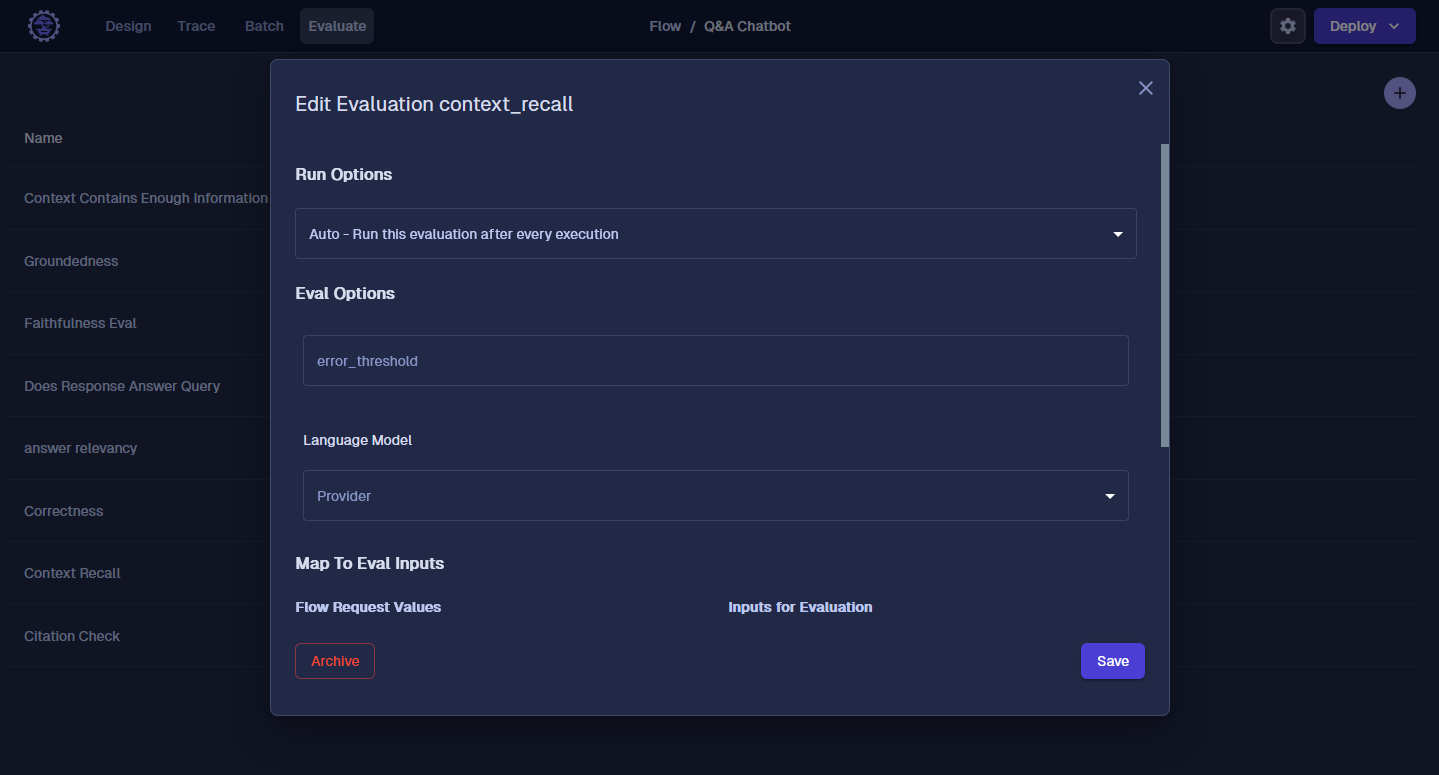
Here is how you should map the other Evaluations.
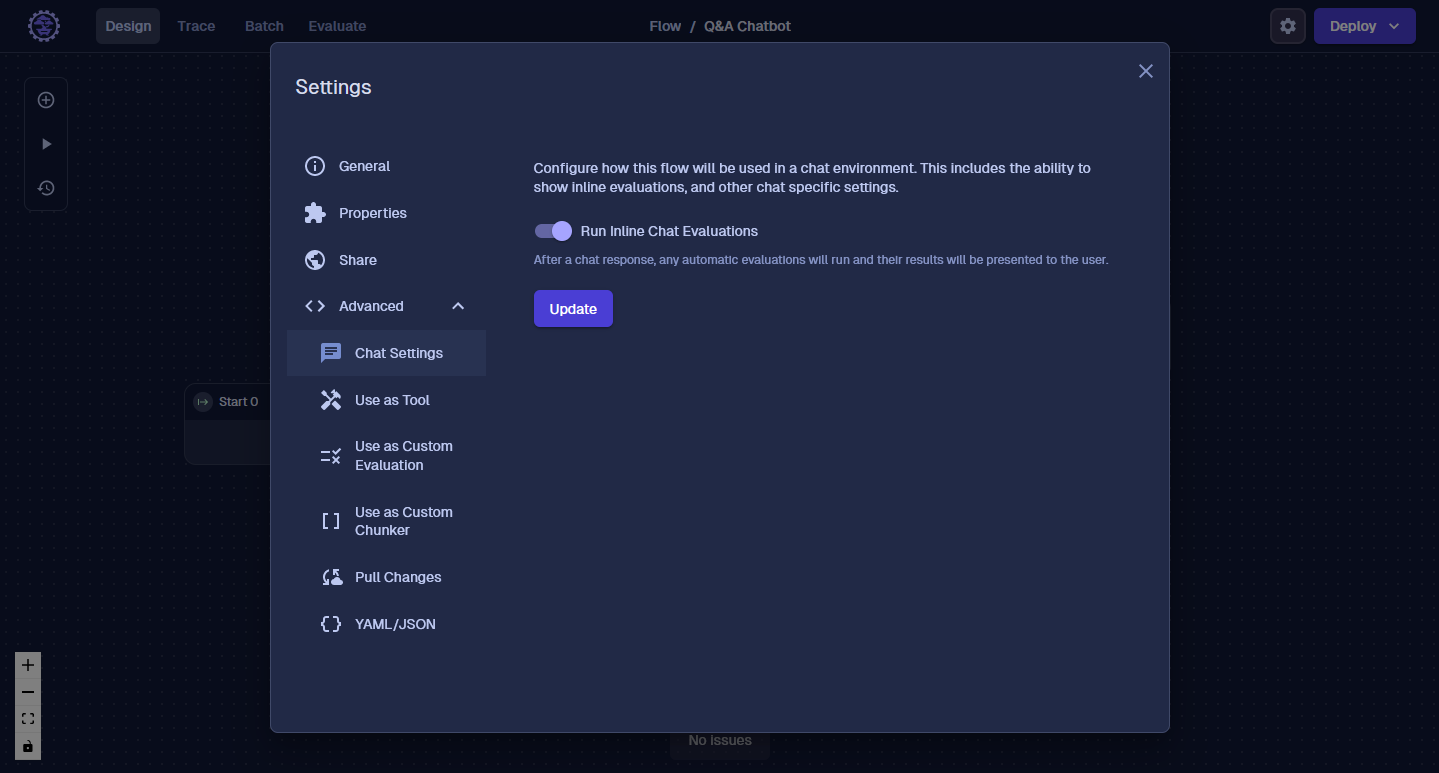
Turn on Inline Chat Evaluations
If the option was selected to run the Evaluation on each request, the Evaluation will run automatically. To make it easy to see what's going on, let's turn on the "Run Inline Chat Evaluations" option. This will let us see the Evaluations run in the Chat Interface.
Do a Test
Let's ask our ChatBot who created the Model T again.
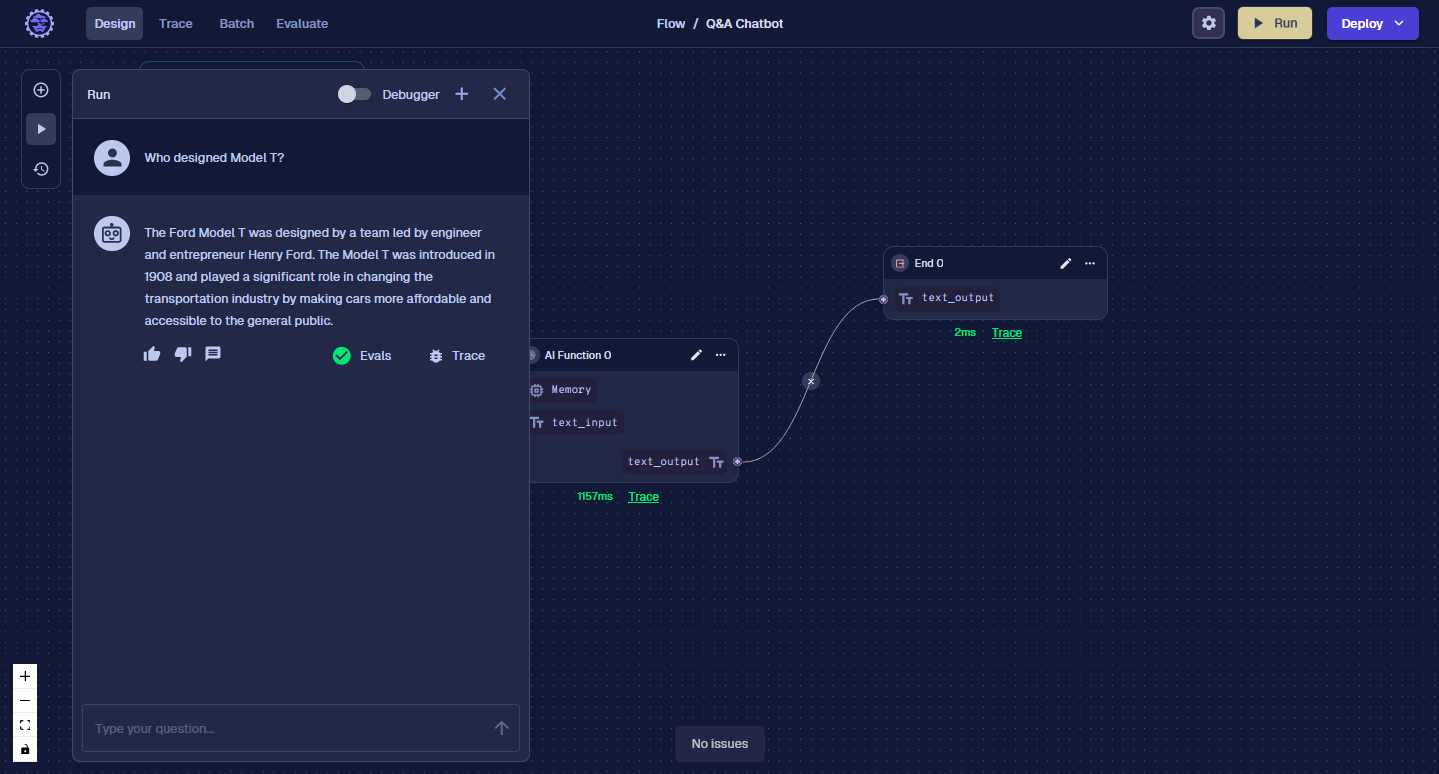
If you see the green checkbox, it means the Evaluations have passed. Click on it, and you can see the details and reason the Evaluation passed or failed. Great, now as we test our ChatBot, we have some automated checks to see how well it's performing. When we’re deploying ChatBots to production, we need to be monitoring the results and making tweaks to our Flows. Because a small change in a Prompt could cause many unintended consequences, it's important to have a set of tests we run before releasing a new version to users. This is where Batches can help.
Next up, we will create some sample questions and answers and run them in Batch. Then we can see how are Evaluations scored each answer that was generated from our ChatBot.