Scrape Web Site
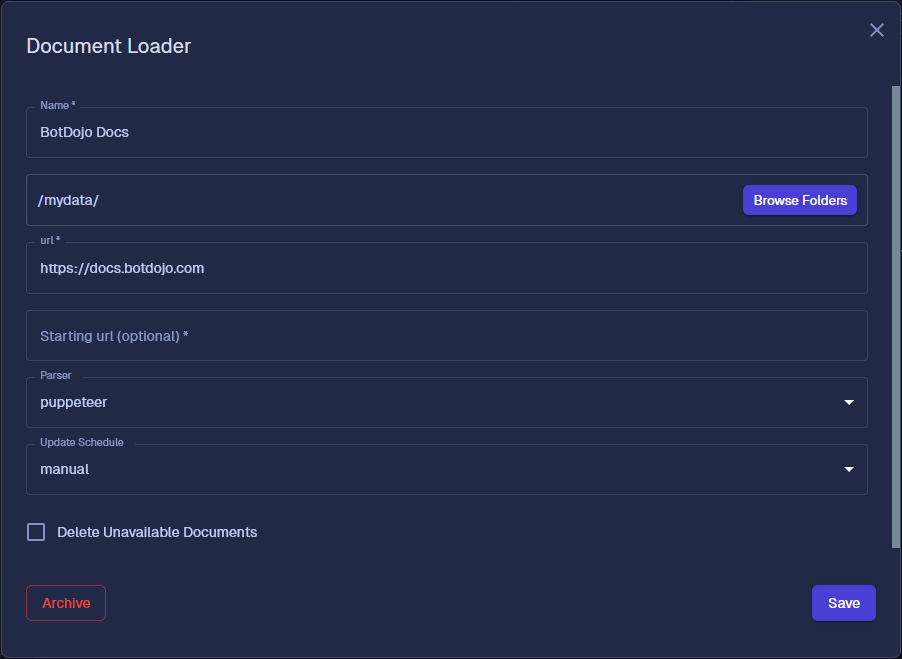
BotDojo provides an easy way to scrape and index data from the web. When creating an index, select the Scrape a Website option.
BotDojo will only scrape 50 pages by default. Contact Us if you need this limit increased.
-
Name: Name of the Loader
-
Document Folder: The name of the folder to store the data
-
Url: URL of the website to scrape. If you only need to scrape a section of a website, then include the full path to the section to scrape.
For example, https://docs.botdojo.com will index the entire website while https://docs.botdojo.com/docs/learn/concepts/vector will only include pages under the docs/learn/concepts/vector path.
-
Starting Url: When scraping a website, BotDojo will navigate to any link found on a page. Optionally provide a starting page to start the crawl.
-
Parser: BotDojo supports two parsers when scraping a website.