Creating a Vector Index
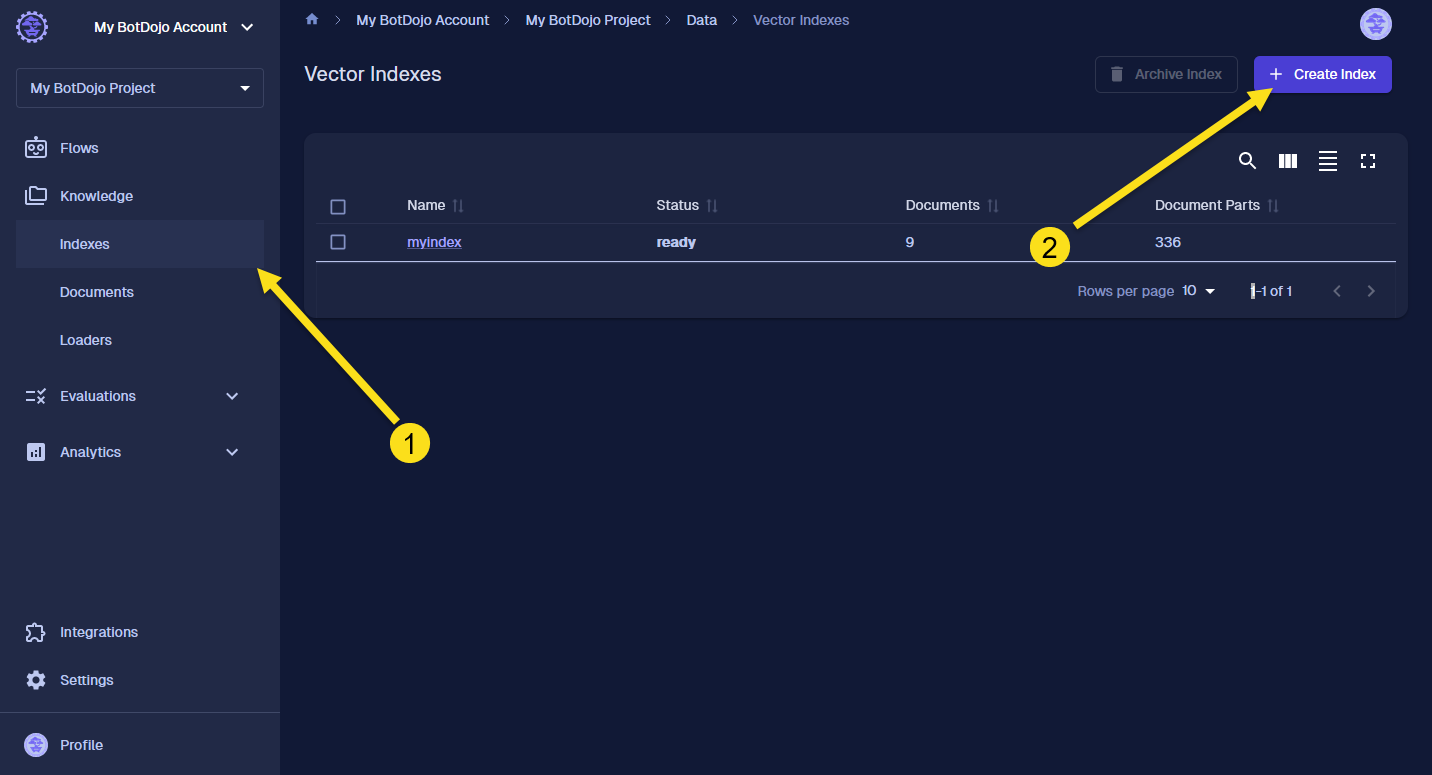
Go to Vector Indexes
To create a Vector Index, select Data from the left navigation. Then click Create Index.
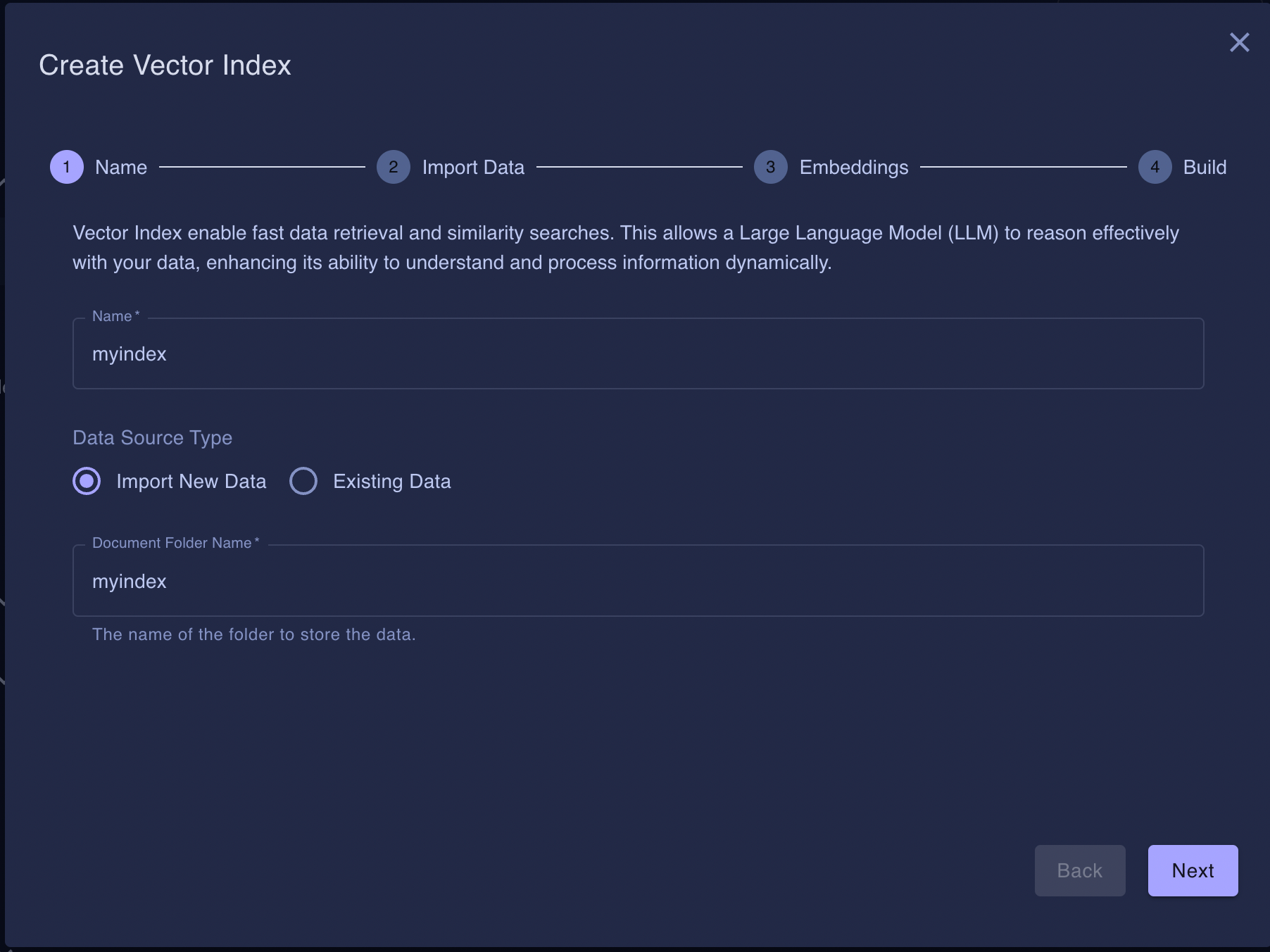
Name and Folder Name
First, we need to name your Vector Index and choose the location where your data will be stored.
-
Name: Pick a name for your Vector Index.
-
Data Source Type:
- New: Import new data to Vector Index.
- Existing: You have previously imported data and want to create a new Vector Index on the same data.
-
Document Folder Name: This is the location where the data will be stored in your BotDojo project. By default, it will be the same as the Name.
Why would you create multiple indexes on the same data?
Creating multiple indexes on the same dataset can be crucial for optimizing performance for specific use cases. Each parameter, such as the choice of embedding model, chunking strategy, and Index size, can significantly influence the effectiveness of a Vector Index. BotDojo facilitates the creation and testing of multiple Vector Indexes, allowing you to evaluate and determine which configuration yields the best results for your particular application.
Import your Data
BotDojo provides multiple ways to import your Data.
-
Upload Files: The easiest way to get started is to upload your files to the Document Folder.
-
Upload Zip: If you have a large number of files (like over 1000), then compress your data into a zip file and upload it. This will preserve the folder structure of your zip and is the most efficient way to import a large volume of files.
-
Scrape a Website: If you want to scrape a publicly facing website. See Data Loaders - Scrape Website
Coming Soon
- Notion
- Google Docs
- Microsoft Office 365
- Salesforce
Contact Us to let us know what we are missing
Embeddings
Embeddings are numerical representations of text that capture semantic meaning, allowing the model to understand and compare the similarity between different pieces of text.
If you are new to Vector Indexes and Embeddings, the following settings are a good starting point.
- Provider: OpenAI
- Model: Text Embedding 3 Large
- Text Splitter: By Character
- Chunk Size: 2000
- Chunk Overlap: 20
- Chunk Language: empty (auto-detect)
-
Embedding Provider: Select the provider for the embedding model, such as, OpenAI, Grog, or other supported providers. Each provider offers different embedding models with varying capabilities and performance characteristics.
-
Embedding Model: Choose the specific embedding model from the selected provider. Different models have been trained on different datasets and may have different strengths and weaknesses depending on your use case.
-
Dimensions: Some embedding models allow you to specify the number of dimensions for the embeddings. Higher dimensions can capture more nuanced semantic information but may also increase computational complexity and storage requirements. The default dimension setting is usually sufficient for most use cases.
-
Type: The type of index to use for your embeddings. BotDojo supports two types.
-
Exact: This option means no specialized index is created for your embeddings. While this might be sufficient for smaller datasets, it can lead to slower query performance as the number of embeddings grows.
-
HNSW (Hierarchical Navigable Small World): This is a specialized index designed for efficient similarity search in large datasets. HNSW indexes are particularly useful when dealing with a large number of embeddings, as they significantly speed up the search process by organizing the data in a way that allows for quick nearest neighbor searches. BotDojo supports HNSW indexes for up to 2000 embeddings, making it an ideal choice for applications requiring fast and accurate similarity searches in large datasets.
-
Chunking Strategy
Chunking breaks down large texts into smaller, manageable pieces to improve information retrieval and enhance input quality for LLMs.
- By Character (default): Splits data into character-based chunks.
- By Token: Splits data by words or subwords.
- Custom: Allows for custom chunking strategies.
Key parameters:
- Chunk Size: Determines the size of text chunks for embedding.
- Chunk Overlap: Specifies overlap between adjacent chunks.
- Chunk Language: Selects the language for preprocessing (auto-detected by default).
Learn more about Chunk Strategies and Custom Chunkers
Save and Index
Finally, review your settings and create an Index.
If you want your index to automatically update when data is modified or added, click the Auto Update Index checkbox.
If you have selected 'Upload Zip' or chosen to scrape a website, your data might still be importing. If you check the Auto Update Index checkbox, it will update the Indexes as data becomes available; otherwise, you will need to run the indexing job manually.