Web Scraping
BotDojo’s web scraper is built on Playwright. Each run launches a headless browser, follows your crawl rules, renders pages as a real visitor would, and saves the output into your project as Markdown (with binary assets preserved separately when needed).
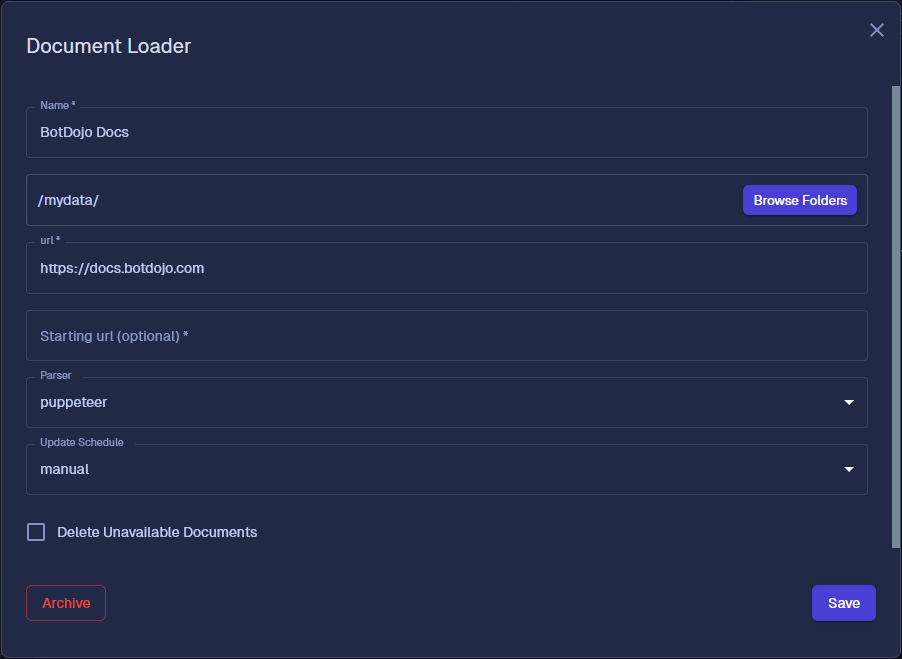
How the Playwright Loader Works
- Provide a starting URL (or a list of starting URLs) and optional advanced settings.
- BotDojo submits a job to the Playwright worker, which navigates pages, waits for your specified condition, and extracts readable content.
- Every page is converted to Markdown, tagged with metadata (
reference_url, title, locale, etc.), and saved in the loader’s target folder. - Attachments such as PDFs, images, or spreadsheets are stored with their original content type so downstream flows can read the native file.
- Subsequent runs compare against previous results and only save new or changed pages. When enabled, stale files are deleted automatically.
Progress is streamed to the UI so you can monitor attempted pages, successes, and failures in real time.
Key Configuration Options
The Playwright loader exposes the same controls you see in the UI:
- Starting URLs – Provide one or more seeds. Advanced settings let you add additional entry points.
- Max Pages & Depth – Cap the crawl to prevent runaway jobs.
- Wait Conditions – Choose when Playwright should scrape: after network idle, after a DOM selector appears, after custom JavaScript, or after a fixed timeout.
- Pre-scrape Actions – Click selectors, run custom JS, or add delays to expand accordions and load lazy content.
- Content Selectors & Exclusions – Target the sections you need while skipping navigation, footers, or cookie banners.
- URL Filters – Include or exclude URLs using glob/regex patterns so the crawl stays in-bounds.
- Browser Controls – Set viewport size, throttle requests, override the user agent, or provide custom headers when you need to mimic a logged-in client.
Open the Advanced Settings accordion in the loader wizard to tune these values. Launch Interactive Mode from the same panel to test selectors in a live browser before running a full job.
Output Structure
- Markdown filenames are derived from the canonical URL (e.g.,
docs.botdojo.com/docs/setup/index.md). - Binary downloads retain their original extensions and capture source URLs in metadata.
- Every saved document includes loader metadata (run ID, timestamps, reference URL) so indexes can filter by fields like
meta.reference_urlormeta.titleduring retrieval.
Operational Tips
- Schedule the scraper around your site’s publishing cadence; the job history tracks duration, page counts, and any errors.
- Combine the loader with Auto Update on your index to refresh embeddings as soon as new pages go live.
- Use metadata filters on the index (e.g.,
language,path) to serve locale-specific or section-specific answers in your flows.
The Playwright-based scraper is the recommended way to keep web properties synchronized with BotDojo content—no extra parsers required.