Agents
Overview
Agent flows are specialized Chat Flows that orchestrate a language model, tool calls, and memory to solve multi-step tasks. Because they publish as chat-compatible flows, their Start node must expose a single user-message string (and optional uploads), and their End nodes return chat-safe output or a structured payload surfaced through the final_output tool. The heart of an agent flow is the botdojo/node/language_model_agent/v2 node, which coordinates prompts, tool schemas, and model responses on every turn.
Agent node
The AI Agent node runs the tool loop for a chat flow. Attach it to your Start node outputs, connect the necessary tools and memory, and the node will manage prompts, model selection, and streaming updates.
Inputs
memory(optional) – Connect a Memory node (see Memory nodes) to govern which past turns are replayed to the model. When a memory connection is present, the agent automatically injects a chat-history placeholder into your prompt template.tools– Provide one or more tool connections. Each tool must publish a name, description, and JSON schema. The agent validates these fields before execution and surfaces schema mismatches during runtime.modelContexts(optional) – Enabled by the Enabled Model Contexts toggle. Connected model contexts contribute cards, prompts, resources, and tools to the agent. During execution the node concatenates their cards into_MODEL_CONTEXT_CARDSand merges their tools with the explicit tool list.validatorTool(optional) – Appears when Validate Agent Turn with Tool is switched on. After the agent believes it is finished, it sends the proposed output to this tool and expects{ success: boolean, message: string }in return. A validator can also declare an optionalagent_turninput property to receive bounded current-turn tool evidence.- Prompt inputs – Any properties defined in the input schema become additional prompt variables. Avoid reserved names such as
session,sessionId,tools,memory,modelContexts,validatorTool,headers,env,now,nowUtc,json,ifEqualTo,ifNotEqualTo, and_MODEL_CONTEXT_CARDS, because the runtime injects those automatically.
Outputs
- Matches the configured output schema. When the schema is a single string property, the node streams natural language back to chat surfaces. For structured outputs, the node injects a virtual
final_outputtool; the agent must call that tool with JSON that matches the schema before the flow can end.
Agent settings
These properties extend the base language-model configuration:
- Use Parallel Tool Calling – Default on. When the model supports parallel function calling, multiple tool invocations from the same turn run concurrently. Disable to enforce sequential execution.
- Show Steps – Streams tool activity to chat clients. Combine with Hide Step Details to show only tool names without exposing arguments or responses.
- Max Iterations – Caps the number of tool-loop iterations. Each iteration allows the agent to review tool output and decide what to do next. If the limit is reached, the node returns an abort message.
- Disable Tools on Last Iteration – Opt in to reserving the final counted iteration for a response without ordinary tools. Structured-output agents retain the internal
final_outputtool so they can still return valid structured data. The default is off. - Warning Threshold Iteration / Warning Threshold Message – Once the iteration counter reaches the threshold, the node injects an assistant message (your custom warning or the default “You only have X iterations left!”) to encourage the model to wrap up.
- Enabled Model Contexts – Adds the
modelContextsinput port and automatically merges model-context tools and cards into the prompt. - Disable Final Output Message – For structured outputs, suppresses the helpful reminder to call the
final_outputtool. If the model forgets, the node raises an error instead of re-prompting. - Custom Final Output Message / Final Output Prompt Tries – Override the reminder text and control how many times the node will nudge the model to return valid JSON (defaults to three attempts).
- Validate Agent Turn with Tool / Validate Agent Turn Tries / Validator Enforcement Mode – Adds the validator tool input, then repeats the feedback loop until
success: trueor a correction budget is exhausted. Blocking (the default) raises a flow error at exhaustion. Advisory retries normally, then publishes the last proposed response when either the validator retry limit or Max Iterations is exhausted; that response did not pass validation. Validator execution errors, invalid or malformed results, and rejected results without a corrective message remain blocking. The enforcement mode is an Agent setting and cannot be selected by the validator. Existing validators can keep an input schema that mirrors the agent output. To inspect tool use, extend that schema with an optionalagent_turnobject; all original output fields stay at the top level. - Add citation references to LLM output – When the model emits inline citation markers such as
[^abc123], the node rewrites the reply to include matching footnotes that link back to the citation sources stored in memory.
Agent turn validation context
When the validator input schema declares agent_turn, the runtime adds a versioned, current-invocation tool ledger:
{
"text_output": "I’m looping in the appropriate team.",
"agent_turn": {
"version": 1,
"iteration_count": 3,
"tool_calls": [
{
"sequence": 0,
"iteration": 2,
"name": "escalateToAgent",
"display_name": "Escalate to Agent",
"status": "success",
"input": "{\"reason\":\"Customer requested a human\"}",
"output": "{\"success\":true}",
"error": "",
"truncated": false
}
],
"truncated": false,
"omitted_tool_call_count": 0
}
}
The ledger contains only model-requested tool outcomes from the current Agent node invocation. It excludes model reasoning, system prompts, prior-session tool calls, attachments, panels, tool schemas, and trace/token events. Each raw tool input, output, and error is capped at 16,000 characters before parsing and redaction, then each sanitized field is capped at 2,000 characters. A tool call's truncated value is true when either cap omits text. The top-level agent_turn.truncated value is also true when any included call is truncated or when more than 32 calls exist; in the latter case, the newest 32 are retained and omitted_tool_call_count reports the number omitted. Common secret-bearing fields, bearer tokens, and signed-URL credentials are redacted. final_output is excluded from the ledger because the proposed output is already present at the top level.
If the validator does not declare agent_turn, the runtime sends exactly the legacy output-only payload. On { "success": false, "message": "..." }, the message is returned to the agent as corrective feedback. In Blocking mode, exhausting the validator retry limit or Agent iteration limit raises a flow error. In Advisory mode, the runtime publishes the last proposed response at exhaustion even though it did not pass validation. Validator execution errors, invalid or malformed results, and rejected results without a corrective message always raise an error.
Language-model overrides (temperature, max tokens, top-p, frequency penalty, streaming behaviour, and provider-specific settings) remain available through the Function Configuration object the node inherits from standard LLM nodes.
Model Context
Model Context nodes bundle prompts, tools, and supporting resources into a reusable package that the Agent node can mount at runtime. Each package exports a botdojo/interface/model_context object that follows the Model Context Protocol (MCP) shape: it exposes a canonical URI, structured cards, prompt definitions, resource lookups, and helper tools for enabling or disabling the context from the chat loop.
Model Context node
- Combine Tools, Prompts, and Resources in a single node. The node emits an interface the agent can auto-discover, and downstream flows can register multiple contexts with different prefixes and descriptions.
- Resources use
mcp://URIs (for example,mcp://sales-playbook/card) so external MCP clients and BotDojo agents reference the same identifiers. If no explicit card resource exists, the runtime renders one from the node configuration using the default card template. - The node also exposes helper tools such as Model Context Search and Model Context Enable, mirroring MCP’s management verbs so agents can list or attach contexts mid-conversation when you expose those tools.
Relationship to the Agent node
- When the Agent node’s Enabled Model Contexts toggle is on, connecting one or more Model Context nodes adds their tool definitions to the agent automatically. You do not need to wire the same tools twice.
- During prompt rendering the agent fetches each context card and concatenates the markdown into the
_MODEL_CONTEXT_CARDSprompt property. Cards typically include the context name, description, prompt summaries, and resource links, giving the model portable documentation for the attached capability. - Model context prompts appear alongside your primary system and user prompts. The agent will respect
importantprompts in the context package and treat them as supplemental instructions, just like an MCP-compatible client would.
Model Context vs. direct tools
- Standalone tools export a schema and description only. You must document usage in your core prompt, and any change requires updating that prompt or schema metadata manually.
- Model Context packages carry a curated set of tools plus a rendered card inside
_MODEL_CONTEXT_CARDS. The card walks the model through prerequisites, argument patterns, and follow-up expectations without bloating the main prompt. - Cards can be generated dynamically (for example, with fresh resource lists), so the guidance stays in sync with the tools the context exposes.
- Agents can enable or disable whole contexts at runtime, keeping the active tool list lean while still letting the model discover additional capabilities through the MCP-aligned management tools.
Prompting with Model Context
Include the _MODEL_CONTEXT_CARDS variable inside your agent prompt to hand the packaged guidance to the model. Use triple braces ({{{…}}}) to preserve the markdown structure produced by the cards.
If you expose multiple contexts, the cards are appended in the order they are connected to the Agent node. Consider adding short headings in your system prompt to help the model quickly scan the available capabilities.
Example configurations
- Knowledge packs – Pair a Model Context node with curated prompts and a document resource (for example, a pricing FAQ rendered as markdown). Connect it to an agent to give sales teams grounded collateral without embedding it directly in the primary prompt.
- Dynamic tool suites – Use a Model Context Manager to aggregate several Model Context nodes (search, calculators, integrations). Agents can then enable or disable entire suites at once via the MCP-aligned enable/disable tools.
- External MCP clients – Because BotDojo adopts the Model Context Protocol, flows that publish a Model Context node can also serve MCP consumers. The same cards and URIs are available whether a conversation runs in BotDojo chat or through an MCP-compatible IDE.
Resources
Resources let agents fetch dynamic capability bundles on demand instead of hard-wiring every tool up front. Providers register botdojo:// URI templates with the shared ResourceFactory, and the agent resolves those URIs through the same matcher used by external MCP clients.
- Providers advertise URI templates, metadata, and optional operations. When the agent (through the Resource MCP) calls
get_resource,packages/botdojo-core/src/resource/resource.tsmatches the URI, loads the provider, and returns metadata, optionaltext, and any declaredlinksto related resources. getResourcesAndLinkedResourcesautomatically follows those links, so requesting a single URI can also attach secondary resources such as editors or management views.- Resources can be simple documents or structured references. Metadata includes provider ids, user-friendly titles, icons, and default tool prefixes, letting the agent reason about what it just mounted.
Model Context resources
- Providers can return
mimeType: botdojo/mcpalongside amcparray. The Agent node mounts those model contexts immediately, merging their tools, prompts, and_MODEL_CONTEXT_CARDSguidance into the active run (FlowMcpNode.getResourceProvider,BatchMCPNode.getResourceProvider, and peers follow this pattern). - The Resource MCP (
packages/botdojo-wrappers/src/botdojo-mcp/resourceMcpNode.ts) exposeslist,search_for_resource,get_resource, andclose_resource. Agents use these tools to discover providers by name, attach the right context at the moment they need it, and release it when finished. - Linked resources enable progressive discovery—for example, opening
botdojo://document/{id}surfaces links tobotdojo://document/{id}/textandbotdojo://storage/mcp, giving the agent the card and tools required to read or edit the same file.
BotDojo Model Context
BotDojo ships a catalog of resource-backed model contexts that cover core platform operations (packages/botdojo-client/src/store/defaultProviders.ts). Each botdojo://…/mcp URI resolves to an MCP-compliant package with cards and tools the agent can mount mid-conversation.
botdojo://flow/mcpexposes flow discovery, schema inspection, run, and editor tools, so an agent can inspect or even build new BotDojo flows—including other agents.botdojo://batch/mcpunlocks batch creation, dataset wiring, and monitoring so long-running evaluations can be triggered without human clicks.botdojo://storage/mcpgives file-system style access: list directories, open files, write updates, and surface linked document contexts such asbotdojo://document/{id}or/text.botdojo://flow_requests/mcp,botdojo://work_queue/mcp, and dataset-related URIs provide orchestration over live executions, work queues, and training data.- Document edit providers add targeted resources (for example, the Document Edit MCP) that layer revision tools on top of the same files.
Wire the Resource MCP alongside these BotDojo contexts so the agent can search the catalog by capability, mount what it needs to open documents, launch batches, or manage other flows, and cleanly close contexts once the task is complete.
Prompts
Agent prompts are Handlebars templates made of ordered messages. Understanding how each segment is populated keeps your agent stable and deterministic.
- System prompt – Provides the non-negotiable instructions for the session. Because the AI Agent node re-renders the system messages on every iteration, keep them static and idempotent. Use them for role definition, tool usage rules, and constraints, not for storing dynamic state.
- Chat history – Insert a
chat_history_placeholdermessage or use the{{CHAT_HISTORY}}block inside abotdojo_prompt. The memory connection decides what appears here: Buffer Memory slices the last N turns, while Compact Memory compresses older messages but lets you expand them later. The raw conversation remains in session state so you can audit or expand it, even if the memory returns a condensed view to the model. - User message – The final user message typically renders
{{text_input}}(or whatever your Start-node property is named). After the agent responds, the memory node records both the assistant output and, optionally, a sanitized version of the user message if you configured Buffer Memory’s override behaviour. - Special variables and helpers – The runtime preloads several values for templates:
session– The session-state variable bag for the conversation.env– Project variables without secrets, useful for pulling configuration or feature flags.headers– Any inbound request headers, allowing channel-specific logic.sessionId– The current flow session identifier for the active chat/run._MODEL_CONTEXT_CARDS– Markdown cards generated from connected model contexts.format_instructions– Auto-populated when the model must return structured JSON.- Handlebars helpers such as
{{now}},{{nowUtc}}(ISO 8601 UTC),{{json}},{{#ifEqualTo}}, and{{#ifNotEqualTo}}are registered globally for convenience. - Within a
botdojo_prompt, you can mark sections usingSYSTEM_PROMPT:,USER_PROMPT:,ASSISTANT_PROMPT:,CHAT_HISTORY, andOUTPUT_SCHEMAto emit structured chat messages without crafting multiple template entries.
Because these variables are reserved, avoid reusing their names as custom inputs. If you need additional context, add new properties to your Start node schema and reference them directly in the prompt.
Intermediate steps
When the agent invokes tools, BotDojo surfaces the intermediate steps in chat interfaces like the one below.
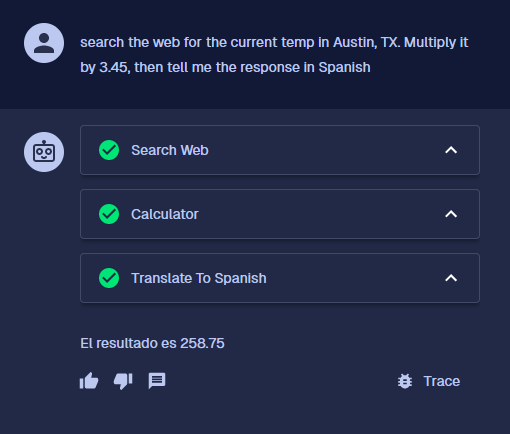
Example
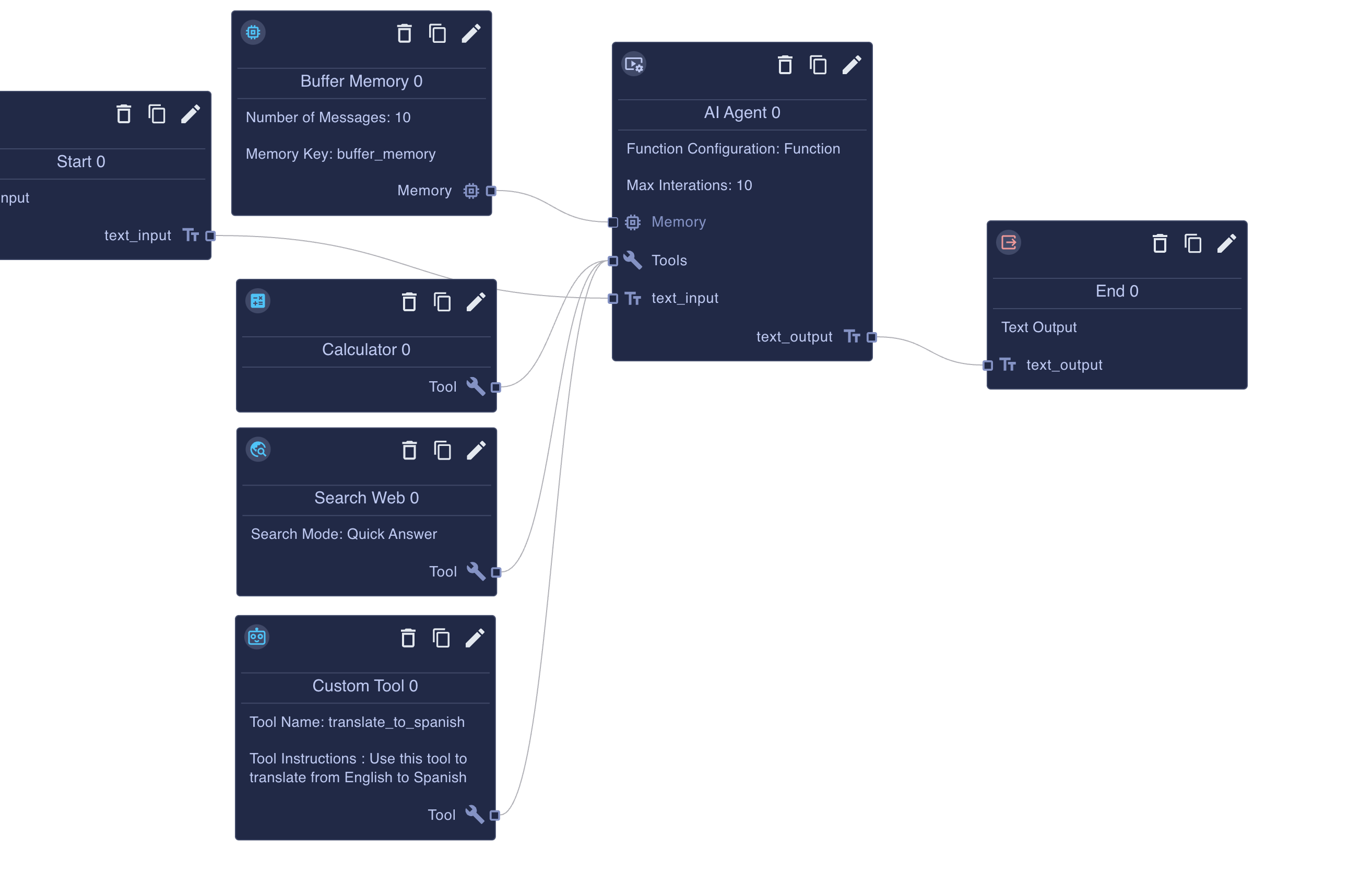
Click the image above to clone an example agent into your project. Ask it search the web for the current temp in Austin, TX. Multiply it by 3.45, then tell me the response in Spanish and watch the agent coordinate multiple tools to build the answer.
Working with vector indexes
Vector indexes give agents durable, grounded knowledge. They blend dense embeddings for semantic recall with rich metadata so prompts can cite, filter, and reason over the right slices of your corpus.
Bring data in with Data Loaders
- Connect Data Loaders to sync documents from SaaS systems (Salesforce, Confluence, Jira, OneDrive), storage buckets, or public websites. Loaders deposit raw files into the project’s Documents area and schedule re-index jobs when content changes.
- Upload one-off PDFs, Markdown files, or transcripts directly on the Data page when you need an immediate addition. Manual uploads share the same storage pipeline, so downstream chunkers and embeddings behave consistently.
- Document storage retains original files, extracted text, and metadata history. Tuning a loader or editing a file and rerunning the index will only re-embed the affected chunks.
- Loader runs emit job logs in the index detail view, letting you trace ingestion errors, throttle misbehaving connectors, or trigger manual retries before agents serve stale answers.
Metadata enrichment and filters
- Each document and chunk automatically captures metadata (file name, logical path, content type, timestamps). Markdown front matter becomes part of the same JSON payload, so attributes like
productLine,region, orconfidentialityarrive ready for filtering. - Edit metadata from the document viewer to add canonical URLs, ownership tags, or compliance flags. Re-indexing merges those edits back into the vector store without forcing a full reload.
- Retrieval nodes expose a
metaDataobject alongside the snippet text. Use it inside prompts for citations, conditional logic, or to feed downstream LLMs richer context. - Mirror critical metadata into session state or analytics events so you can audit which sources influenced a given answer and tighten governance over time.
Custom chunking strategies
- Default chunkers split by heading or token count, but nuanced corpora gain accuracy from bespoke Chunker flows. Build a flow with the chunker start/end schemas, enable Use as Custom Chunker, and reuse it across indexes.
- Custom chunkers can enrich metadata—attach hierarchical breadcrumbs, summaries, or security labels at the same time you segment the text.
- Create parallel indexes with different chunk sizes, overlap, or chunker flows, then compare retrieval quality with batches or evaluation suites before standardising on one configuration.
- Inspect chunk outputs with Index to Parquet or document previews before turning agents loose, ensuring each chunk has the right balance of context and specificity.
Nodes that work with indexes��
- Search Index tool (reference) lets the agent call a vector search as a tool. Configure the index, top-k, and optional filter inputs so the model can pull grounded snippets mid-conversation.
- Search Index function node (Retriever) performs the same semantic lookup directly in a flow. It accepts an optional
filterinput, making it ideal for pre- or post-processing before the agent sees the results. - Index Interface node (reference) outputs a handle to the index so code nodes, evaluators, or background jobs can add documents, stream embeddings, or export data.
- Index to Parquet and Get Documents utilities convert filtered slices of the index into Parquet files or raw document arrays for audits, fine-tuning datasets, or sandbox experiments.
Hybrid semantic and structured queries
- Vector retrieval supports metadata-aware filtering. Set the retriever or tool
filterto{ "type": "sql-like", "sqlWhere": "meta->>'region' = 'EU' AND meta->>'productLine' = 'Widgets'" }to prune candidates before similarity scoring runs. - Call
queryMetadata({ type: 'sql-like', sql: "SELECT meta FROM index_table WHERE meta->>'category' = 'Policy'" })on an index interface when you need structured lookups without embeddings. The backend rewrites the SQL against a whitelisted view of your index, so you can safely fetch document IDs, titles, or custom attributes. - Combine both approaches: issue a metadata query to identify relevant document paths, then feed the resulting condition into the retriever filter. The agent enjoys semantic ranking while staying scoped to compliant, high-confidence sources.
- Echo filter criteria into the agent prompt (e.g., “Cite only EU policies updated this quarter”) so the model understands why certain documents were in scope and can explain its reasoning.
Agent tools
Agent Tools are the capabilities your agent can call during a run. You can:
- Add built-in agent tool nodes from the Agent Tools category (web search, math operations, and more).
- Wrap sub flows as tools by adding the Sub Flow Tool node and pointing it at the sub flow you built.
- Publish separate flows as reusable tools by enabling Use as Tool in flow settings and providing a tool name and description.
Sub flows are quick to add within a single flow but cannot be reused elsewhere. Dedicated flows have a higher setup cost yet offer versioning, reuse across projects, and richer packaging. Combine both approaches to give your agent precisely the capabilities it needs.
For memory strategies and configuration, continue to Memory nodes.